Introduction
Open-source generative AI models – such as Llama (Meta), Mistral (Mistral AI), and Phi-4 (Microsoft) – have demonstrated significant advancements. The innovation from incredible teams worldwide is driving a wave of use-case exploration. However, recent developments, particularly DeepSeek’s impressive cost-to-performance ratio, have made businesses take generative AI even more seriously, prompting them to assess its practical applications.
This article provides a perspective on a specific, yet crucial, use case – extracting data from business documents like PDFs to build structured databases. While generative AI is undoubtedly innovative, deploying it for this use case may not always be the best approach. Organisations must carefully consider their needs, as specialised AI solutions often outperform generative models in efficiency and accuracy for specific tasks.
Before diving in, it is essential to remember that AI is a broad field, with generative AI being just one subset of it. Other deep learning applications, while less headline-grabbing, remain critical in solving practical challenges.
The Business Need
Manual data extraction has become a thing of the past. In the era of digital transformation and cloud migration – accelerated further by the COVID-19 pandemic – organisations have adopted automated document processing solutions. These range from basic OCR (Optical Character Recognition)-based tools to sophisticated systems employing robotic process automation (RPA) for legacy environments.
Structured data is vital not only for automating decision-making processes but also for building databases that enable further solutions. These solutions can include advanced analytics, integration into CRM systems, marketing strategies, compliance tracking, and broader enterprise planning. However, document exchanges still heavily rely on PDFs or, in some cases, paper-based formats. While Electronic Data Interchange (EDI) exists, PDFs dominate as the preferred communication medium for invoices, contracts, receipts, and compliance documents. According to industry reports, 98% of businesses identified PDFs as their primary format for external communication.
Given the reliance on PDFs, OCR and entity text extraction have become indispensable components of AI-driven workflows. They address critical challenges by enabling actionable insights and seamless integration into workflows such as CRM systems, compliance tracking, and marketing strategies.
These tools allow businesses to turn unstructured data into actionable insights, driving both operational efficiency and strategic outcomes.
So, is deploying a generative AI model the most effective way for document processing?
Comparing Generative AI and Traditional AI for Document Processing
Generative AI, such as OpenAI’s GPT-4, Google’s Gemini, and Anthropic’s Claude, can analyse documents, extract data, and answer contextual queries. Open-source models such as Llama can also be deployed for these tasks and combined with decision-making processes or used to distil insights.
On the other hand, traditional AI frameworks like AWS Textract, Azure Form Recognizer, and Google Document AI are specifically designed for structured document processing. These solutions leverage OCR and machine learning models tailored for structured data extraction, ensuring high accuracy and efficiency in handling large-scale document workflows.
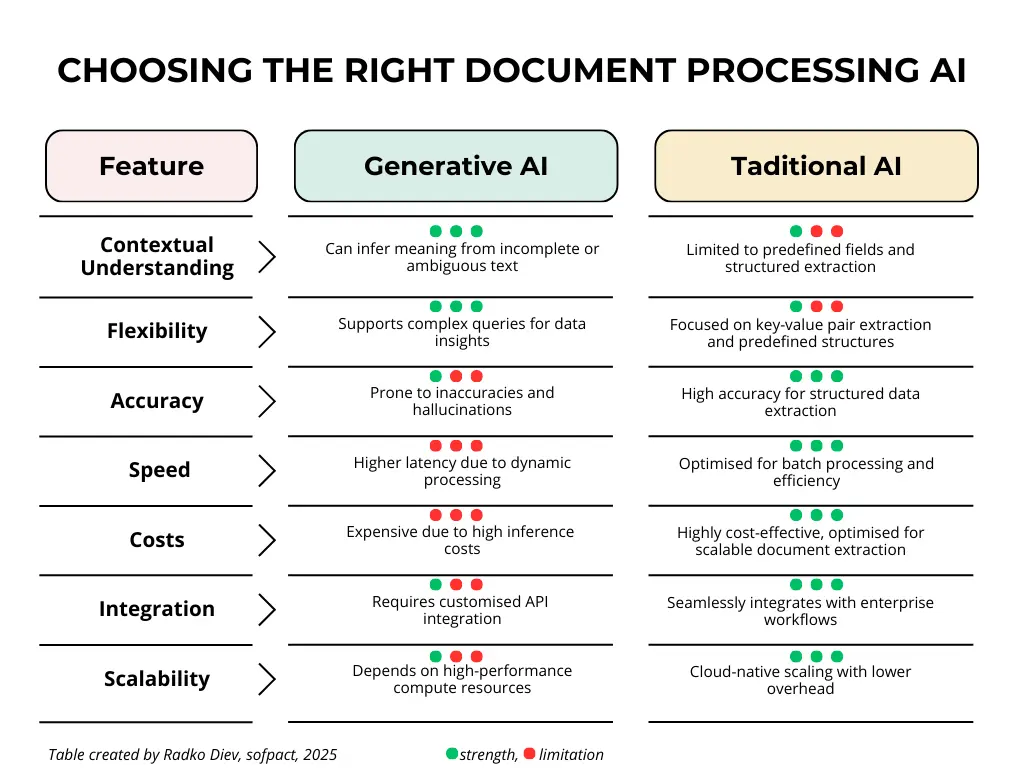
The Right AI for the Right Task
Despite the excitement around generative AI, not all AI applications require LLMs. For document processing – where accuracy, cost, and efficiency are paramount – traditional AI frameworks like AWS Textract, Azure Form Recognizer, and Google Document AI remain the optimal choice.
Generative AI holds potential for hybrid workflows, such as post-processing extracted data to provide insights, detect anomalies, or answer contextual questions.

