Introduction
AI applications are becoming more accessible, often without upfront costs. Providers such as Microsoft, Google, AWS, and Meta offer many pre-trained solutions, ranging from local large language models (LLMs) to autonomous agents and chatbots. Tools like natural language processing (NLP) for sentiment analysis or retrieval-augmented generation (RAG) for dynamic knowledge bases are transforming organisations worldwide. If your organisation has yet to adopt an AI application, it is only a matter of time.
The key differentiator for successful AI adoption is data abundance and quality.
By 2025, up to 80% of all business data will be unstructured. While unstructured data has potential “as is,” AI agents are increasingly helping to structure it through parsing, classification, and extraction. However, relying solely on AI to address data quality is risky. This article provides a practical roadmap to help executives prepare their data for AI adoption.
Structured vs Unstructured Data
The table below visually compares structured and unstructured data, highlighting key differences such as definitions, examples, storage types, and their role in AI applications.
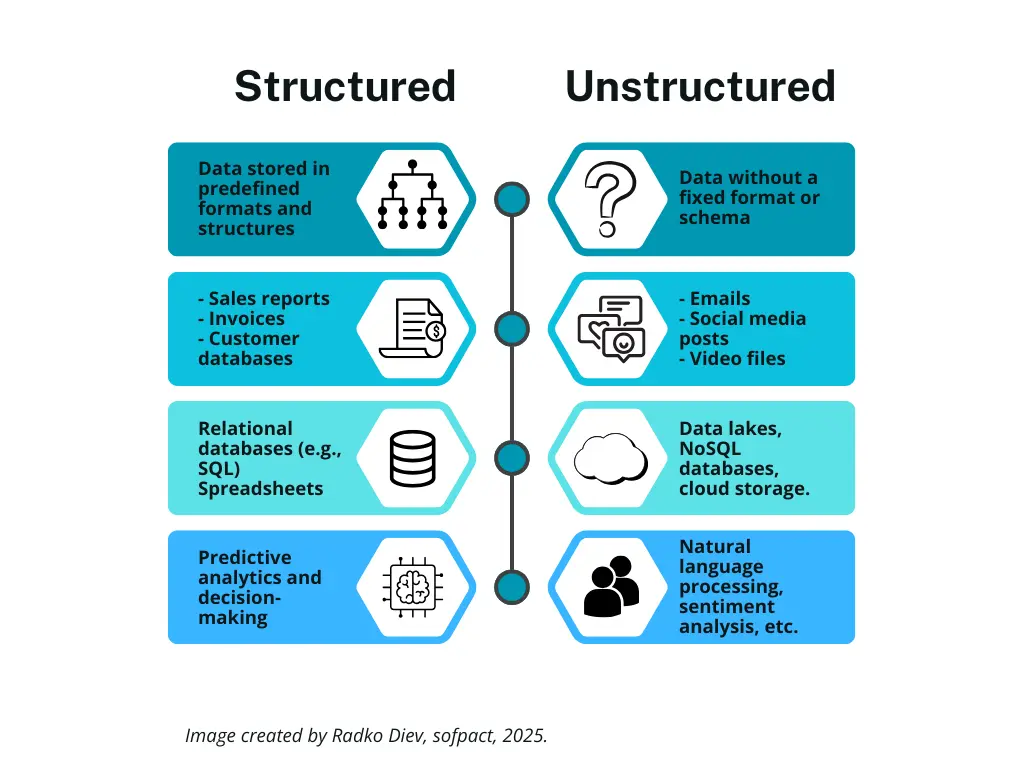
Figure 1: A visual comparison of structured and unstructured data, showcasing their definitions, examples, storage options, and AI potential.
Why Data Preparation Matters
1. Quality In, Quality Out
AI applications cannot fix bad data. Instead, they magnify distortions, biases, and inaccuracies. Faulty models created from poor-quality data result in substandard decision-making. Duplicates, inaccuracies, and inconsistent records can cost organisations 15–20% of their revenue.
2. Reduced Risks
Incomplete or inconsistent data can result in compliance breaches, inaccurate financial forecasts, and poor decisions. Proper data validation and cleansing are essential for avoiding these pitfalls and ensuring adherence to ethical and regulatory standards (e.g., GDPR, HIPAA, or industry-specific regulations).
3. Mitigating Bias
Bias in AI models often stems from skewed or incomplete datasets, potentially leading to discrimination in hiring, customer service, or loan approvals. Addressing bias at the data preparation stage helps ensure fairer, more accurate AI-driven decisions.
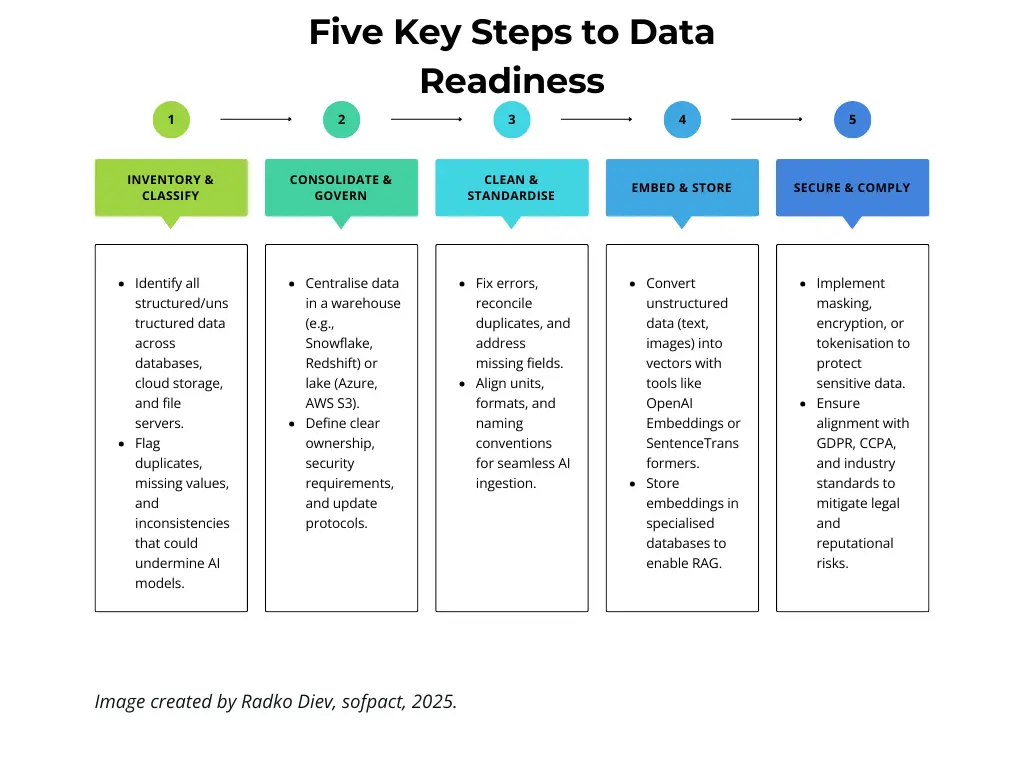
Five Key Steps to Data Readiness
Figure 2: An infographic summarising the five essential steps to prepare your data for AI adoption.
Aligning Data with AI Use Cases
- High-Preparation Use Cases:
– Predictive Analytics: Sales forecasts, inventory management, and other forward-looking tasks rely on consistent, high-quality data.
– Automated Decision-Making: Fraud detection or loan approvals demand accurate, bias-free datasets to minimise risks. - Low-Preparation Use Cases:
– Chatbots & Support: Reusing existing FAQs or chat transcripts offers quick wins with minimal data reformatting.
– Sentiment Analysis: Aggregating social media or customer feedback into embeddings reveals trends with little extra setup.
The Role of RAG and Autonomous Agents
- Retrieval-Augmented Generation (RAG)
– Integrate large language models with your internal data for on-demand document referencing – no need for frequent retraining. This approach is ideal for industries like finance or retail, where information changes rapidly. - Autonomous Agents
– Automate multi-step workflows (e.g., compliance checks, approvals) provided the underlying data is trustworthy and accessible. The effectiveness of these agents depends on strong data pipelines and governance.
Practical Tips for Executives
- Collaborate Across Departments:
– Engage IT, Operations, Compliance, Finance, Marketing, HR, and other teams to ensure shared responsibility for data accuracy and security. - Start Small, Scale Fast:
– Pilot a simple AI project (e.g., an internal Q&A chatbot) to demonstrate feasibility and gain stakeholder buy-in. - Focus on Measurable Outcomes:
– Align data initiatives with specific goals (e.g., cost reduction, revenue growth, compliance) for clear ROI. - Invest Strategically in Tools:
– Data lakes, vector databases, and AI frameworks (e.g., LangChain, LlamaIndex) can streamline development (avoid overinvestment without proven use cases). - Iterate and Improve:
– Data readiness is an ongoing process. Continually revisit governance policies, quality metrics, and model performance to stay aligned with business needs.
Conclusion
Preparing your organisation’s data for AI is more than a technical step – it is a strategic imperative. By auditing data sources, consolidating and governing them effectively, cleaning and standardising formats, and leveraging tools that support both structured and unstructured data, you establish the groundwork for scalable, accurate AI systems.